
Rewriting Our Media Hosting Infrastructure
Jun 16, 2025

TL;DR: We migrated 4M media files from Bunny.net to GCP, replaced our FFmpeg setup with Transcoder API, and centralized uploads across our platform. It cut costs, simplified infrastructure, and improved the user experience.
When we first embarked on building our media hosting infrastructure, we made what seemed like a straightforward choice: Bunny.net for both storage and CDN services. The decision made perfect sense at the time, their platform excelled at handling images, which was our primary need.
But as our platform evolved, so did user expectations. We introduced video support to meet growing demand, which brought a host of new technical challenges, especially around video compression, format optimization, and web delivery. Our initial solution? A self-hosted FFmpeg server to handle video conversions.
That setup worked, for a while. But as our user base scaled, so did the cracks:
Long upload and processing times
Poor feedback during upload
Frustrated users, especially those uploading video
This is the story of how we completely rewrote our media infrastructure to improve speed, reduce costs, and support a much better user experience.
Key Challenges and Goals
We kicked off the rewrite by identifying the most pressing challenges and what success would look like:
Traffic Volume: 1.3 billion requests per month meant infrastructure choices had major cost implications.
Cost Efficiency: Optimizing CDN and storage usage was crucial to stay sustainable.
Processing Speed: Slow transcoding led to poor user experience, this had to improve.
Maintenance Overhead: Our in-house FFmpeg setup demanded too much engineering time.
User Experience: The upload → process → feedback loop had to be fast and clear.
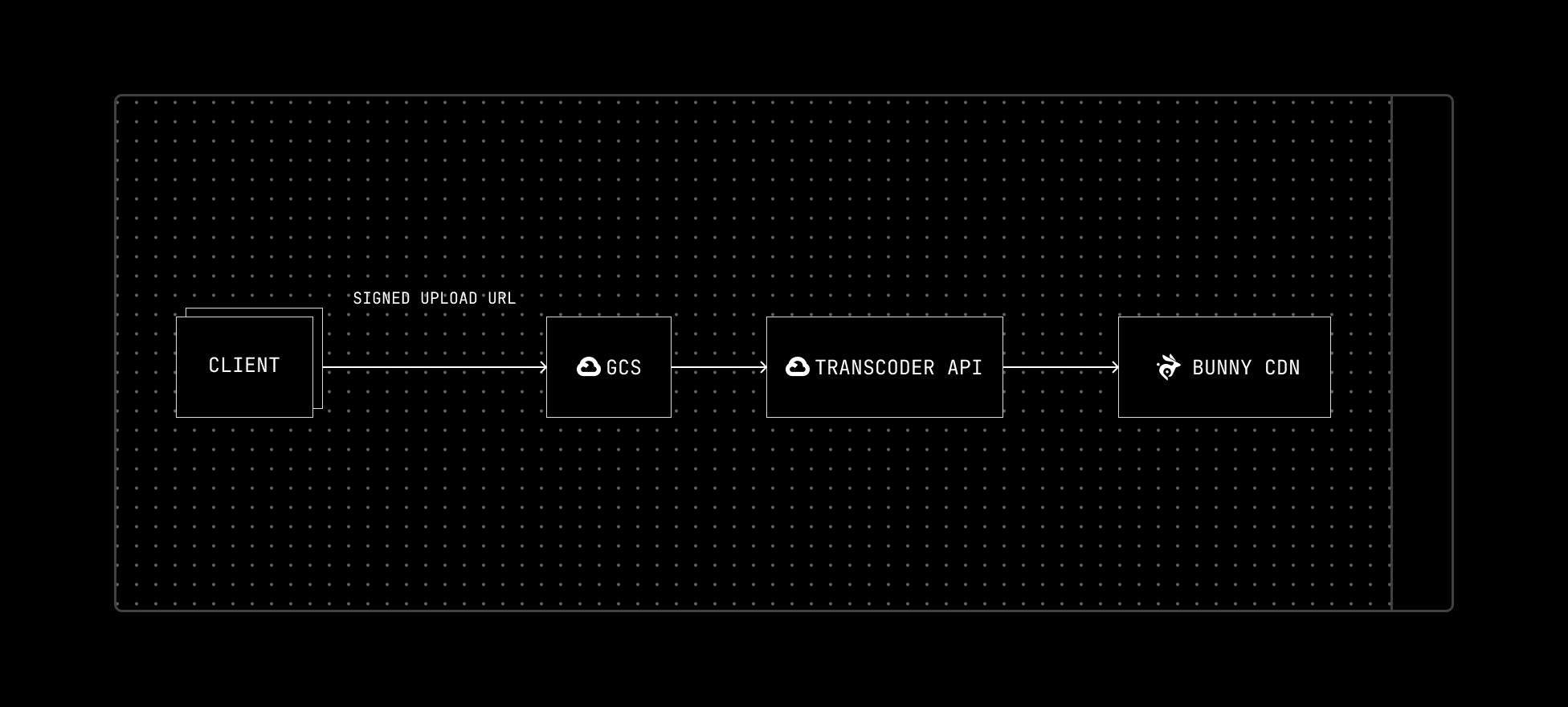
The New Stack
We rebuilt our media infrastructure from the ground up using a hybrid approach:
Storage: Google Cloud Storage with direct upload via signed URLs. Since most of our services already run in GCP, it made sense to use their object storage solution for tighter integration and operational simplicity. What we were primarily looking for was support for signed upload URLs, so we could let clients upload directly without routing media through our own servers first.
Processing: GCP’s Transcoder API replaced our custom FFmpeg server
Delivery: Bunny CDN remains, now with permanent caching to reduce origin fetches
This combination gave us the performance and reliability we needed, while drastically cutting down on maintenance.
Centralizing Media Uploads
As we audited our system, we realized that media was being uploaded from all over the platform:
User profile pictures
Custom fonts for branding
Workspace media (images and videos)
Upload forms across various flows
Media synced from Instagram
Over time, each of these had been built independently, with unique logic and inconsistent validation. This fragmentation caused bugs, complicated onboarding, and increased technical debt.
What We Changed
We built a centralized media upload handler, a unified and consistent pipeline that handles all media uploads, regardless of source (web, mobile, or internal tools). This abstraction ensures that every piece of media goes through the same flow, with standardized:
Validation: File type, size, dimensions, and metadata are checked upfront to prevent bad data from entering the system.
Processing: Transcoding, resizing, and thumbnail generation are now consistent across all media types.
Storage hierarchy: All files are stored following a predictable, organized structure in GCS, which makes them easier to locate, manage, and audit.
This change reduced edge-case bugs, removed duplicate logic across platforms, and significantly simplified our codebase. It also paved the way for user-facing improvements like:
Upload progress indicators: Real-time feedback on upload status, especially important for larger files
Thumbnail previews: Instant visual confirmation of successful uploads
Failure recovery: Automatic retry mechanisms and clearer error messages make failed uploads less frustrating and easier to debug
By consolidating upload logic into a single, robust handler, we’ve made our system both more resilient and easier to extend.
Migration Strategy
Once the new infrastructure was ready, we had to migrate 4 million media files, roughly 4TB of data, without impacting users. The stakes were high: no corruption, minimal downtime, and a seamless cutover.
How We Did It
Resumable Migration Script
The migration logic ran as a GCP Cloud Run job, allowing us to scale it horizontally and run it on-demand with minimal overhead. The script processed files in batches, with built-in support for resumable uploads and automatic retries to handle transient errors gracefully.
Validation Pipeline
After each file was migrated, we verified it using HEAD requests, checking HTTP status codes, content type, and content length to ensure integrity and match against the source.
Migration Tracking
We recorded each migration in a dedicated collection, capturing:
Old and new URLs
Associated model types and field paths
Timestamps and migration status
This let us track progress accurately and gave us a simple way to revert or reprocess files if any issues (like corruption or mismatches) were discovered post-migration.
Folder Restructure
We reorganized our file layout to a more structured and semantic format
Old structure:/images/[id].jpeg
/videos/[id].mp4
/thumbnails/[id].jpeg
/fonts/[id].woff
New Structure:/images/[id]/original.jpeg
/videos/[id]/original.mp4
/videos/[id]/thumbnail.jpeg
/fonts/[id]/original.otf
This change not only improved clarity and file organization, but was also necessary to align with how the Transcoder API handles input and output paths. Grouping related assets under a shared folder (like a video and its generated thumbnail) made post-processing and access logic significantly cleaner and more maintainable.
Lessons Learned: A Costly Mistake
One thing we didn’t plan well enough: GCP egress costs.
In our validation step, we made a rookie mistake, we used HEAD requests to the new CDN URL for each media file. But since those files weren’t cached yet, every request triggered a pull from the GCP bucket, racking up egress fees.
Multiply that by 4 million and… yeah, ouch.
What we should’ve done was use the GCP Storage API to check file metadata directly, zero egress, same validation. Lesson learned.
🙃 Sometimes you only notice inefficiencies when the invoice shows up.
Despite the surprise cost, the migration was worth it. We now have a cleaner, faster, and more scalable system.
Before & After: UX Transformation
Our users felt the difference immediately.
Before: No upload progress, long waits, confusing errors
After: Clear progress feedback, faster processing, fewer failures
Wrapping Up
Rebuilding our media infrastructure was a major undertaking, one that touched nearly every part of our stack. What started as a fix for slow video uploads turned into a full overhaul of how we handle media across the platform. We replaced fragmented flows with a single, unified pipeline; swapped our self-hosted FFmpeg server for GCP’s managed Transcoder API; and restructured how we store and serve every file.
The impact was immediate:
Upload and processing times were cut by over 50% — small uploads now complete in seconds, and even large videos that once took 5–10 minutes are ready in under 40 seconds.
Upload-related errors dropped dramatically, improving reliability across the board.
Media file sizes shrank by 20–30%, helping us reduce both load times and storage costs.
Engineering overhead dropped to nearly zero, freeing up time previously spent maintaining a brittle legacy stack.
Beyond the numbers, we now have a system that’s easier to reason about, easier to scale, and easier to build on.
Hopefully, this post helps someone out there avoid a few pitfalls, or at the very least, gives you a sense of what a media migration really looks like under the hood.